Unless you’ve been under a rock, and probably, even if you have, you’ve noticed that ‘AI’ is being promoted as the solution to everything from climate change to making tacos. There’s an old joke: how do you know when a politician is lying? Their mouth is moving. Similarly, anytime businesses relentlessly push something, the first question that should come to mind is: how are they trying to make money?
Microsoft, in particular, has, as the saying goes, gone all in rebranding its implementation of OpenAI’s ChatGPT large language model based products as CoPilot, embedded across Microsoft’s catalog. Leaving aside, for the sake of this essay, the question of what so-called AI actually is, (hint: statistics) considering this push, it’s reasonable to ask: what is going on?
Ideology certainly plays a role
That is, the belief (or at least, the assertion) of a loud segment of the tech industry that they are building Artificial General Intelligence – a successor to humanity, genuinely thinking machines
Ideology is an important factor but it’s more useful to place technology firms such as Microsoft back within capitalism in our thinking. This is a way to reject the diversions this sector uses to obscure that fact
To do this, let’s consider Vladimir Lenin’s theory of imperialism as expressed in his essay, ‘Imperialism the highest stage of capitalism’.
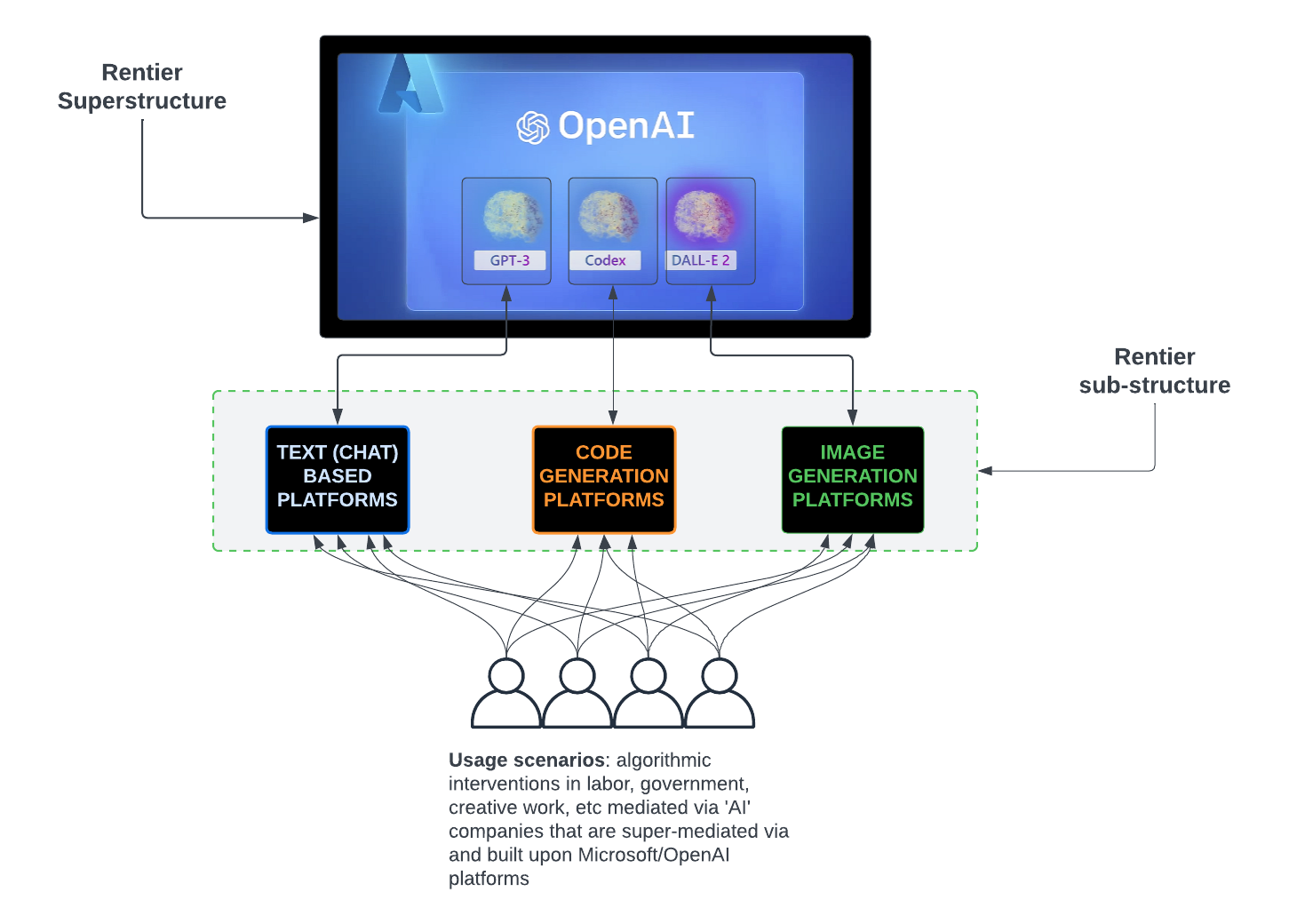
In January of 2023, I published an essay to my blog titled, ChatGPT: Super Rentier.
The thesis of that essay is that Microsoft’s partnership with, and investment in, OpenAI and the insertion of OpenAI’s large language model software, known as ChatGPT into Microsoft’s product catalog, was done to create a platform Microsoft would use to make it a kind of super rentier – or, super landlord – of AI systems. Others, sub-rentiers, would build their platforms using Microsoft’s platform as the backend making it the super rentier – the landlord of landlords.
With this in mind, let’s take a look at this visualization of Lenin’s concept of imperialism I cooked up:
For me, the key element is the relationship between the tendency towards monopoly which leads to stagnation (after all, what’s the incentive to stay sharp if you control a market?) and the expansion of capitalist activity to other, weaker territories to temporarily resolve this stagnation – this is the material motive for capitalist imperialism or as Lenin also phrased it, parasitism.
Let’s apply this theory to Microsoft and its push for AI everywhere:
Microsoft, as a software firm, once derived most of its profit from selling products such as SQL Server, Exchange Server and the Office Suite.
This became a near monopoly for Microsoft as it dominated the corporate market for these and other types of what’s known as enterprise applications.
This monopoly led to stagnation – how many different ways can you try to derive profit from Microsoft Office, for example? By stagnation, I don’t mean that Microsoft did not make money or profit from its dominance, but this dominance no longer supported the growth capitalists demand.
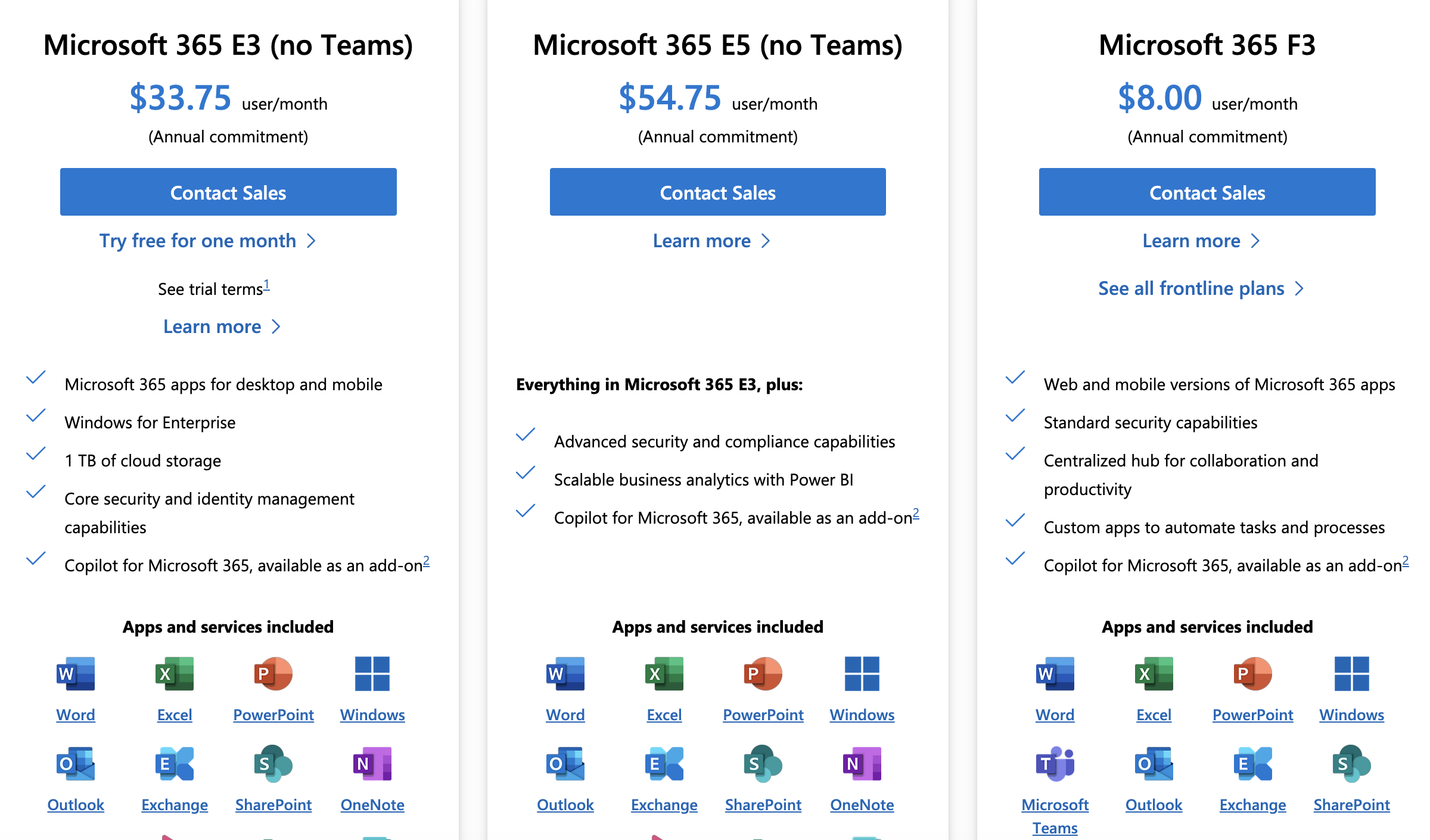
The answer, for a time, was the subscription model of the Microsoft 365 platform which moved corporations from a model in which products such as Exchange would be hosted in-house in corporate data centers and licensed, to one in which there was a recurring charge for access and guaranteed revenue stream for Microsoft.
No longer was it possible for a company to buy a copy of a product and use it even after licensing expired. Now, you have to pay up, routinely, to maintain access.
After a time, even this led to a near monopoly and the return of stagnation as the market for expansion was saturated
Into this situation, enter ‘AI’
By inserting AI – chatbots and image generators into every product and pushing for this to be used by its corporate customers, Microsoft is enacting a form of the imperialist expansion Lenin described – it is a colonization of business process, education, art, filmmaking science and more on an unprecedented scale
But what haunts the AI push is the very stagnation it is supposed to remedy
There is no escape from the stagnation caused by monopoly, only temporary fixes which merely serve to create the conditions for future decay and conflict.
This is written in the spirit of the Request for Comments memorandums that shaped the early Internet. RFCs, as they are known, are submitted to propose a technology or methodology and gather comments/corrections from relevant and knowledgeable community members in the hope of becoming a widely accepted standard.
Purpose
This is a consideration of the information technology options for politically and socially active organizations. It’s also a high level overview of the technical landscape. The target audience is technical decision makers in groups whose political commitments challenge the prevailing order, focused on liberation. In this document, I will provide a brief history of past patterns and compare these to current choices, identifying the problems of various models and potential opportunities.
Alongside this blog post there is a living document posted for collaboration here. I invite a discussion of ideas, methods and technologies I may have missed or might be unaware of to improve accuracy and usefulness.
Being Intentional About Technology Choices
It is a truism that modern organizations require technology services. Less commonly discussed are the political, operational, cost and security implications of this dependence from the perspective of activists. It’s important to be intentional about technological choices and deployments with these and other factors in mind. The path of least resistance, such as choosing Microsoft 365 for collaboration rather than building on-premises systems, may be the best, or least terrible choice for an organization but the decision to use it should come after weighing the pros and cons of other options. What follows is not an exhaustive history; I am purposefully leaving out many granular details to get to the point as efficiently as possible.
A Brief History of Organizational Computing
By ‘organizational computing’ I’m referring to the use of digital computers arranged into service platforms by non-governmental and non-military organizations. In this section, there is a high level walk through of the patterns which have been utilized in this sector.
Mainframes
IBM 360 in Computer Room – mid 1960s
The first use of digital computing at-scale was the deployment of mainframe systems as centrally hosted resources. User access, limited to specialists, was provided via a time sharing method in which ‘dumb’ terminals displayed results of programs and enabled input (punch cards were also used for inputting program instructions). One of the most successful systems was the IBM 360 (operational from 1965 to 1978). Due to expense, the typical customer was large banks, universities and other organizations with deep pockets.
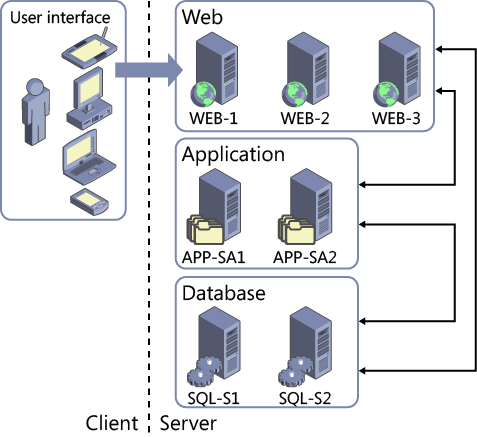
Client Server
Classic Client Server Architecture (Microsoft)
The introduction of personal computers in the 1980s created the raw material for the development of networked, smaller scale systems that could supplement mainframes and provide organizations with the ability to host relatively modest computing platforms that suited their requirements. By the 1990s, this became the dominant model used by organizations at all scales (mainframes remain in service but the usage profile became narrower – for example, to run applications requiring greater processing capability than what’s possible using PC servers).
The client server model era spawned a variety of software applications to meet organizational needs such as email servers (for example, Sendmail and Microsoft Exchange), database servers (for ex. Postgres and SQL Server), web servers such as Apache and so on. Companies such as Novell, Cisco, Dell and Microsoft rose to prominence during this time.
As the client server era matured and the need for computing power grew, companies like VMWare sold platforms that enabled the creation of virtual machines (software mimics of physical servers). Organizations that could not afford to own or rent large data centers could deploy the equivalent of hundreds or thousands of servers within a smaller number of more powerful (in terms of processing capacity and memory) computing systems running VMWare’s ESX software platform. Of course, the irony of this return to something like a mainframe was not lost on information technology workers whose careers spanned the mainframe to client server era.
Cloud computing
Cloud Pattern (Amazon Web Services)
Virtualization, combined with the improved Internet access of the early 2000s, gave rise to what is now called ‘cloud.’ Among information technology workers, it was popular to say ‘there is no cloud, it’s just someone else’s computer.’ Overconfident cloud enthusiasts considered this to be the complaint of a fading old guard but it is undeniably true.
The Cloud Model
There are four modes of cloud computing:
Infrastructure as a service – IaaS: (for example, building virtual machines on platforms such as Microsoft Azure, Amazon Web Services or Google Cloud Platform)
Platform as a service – PaaS: (for example, databases offered as a service utility eliminating the need to create a server as host)
Software as a Service – SaaS: (platforms like Microsoft 365 fall into this category)
Function as a Service – FaaS: (focused on deployment using software development – ‘code’ – alone with no infrastructural management responsibilities)
A combination of perceived (but rarely realized) convenience, marketing hype and mostly unfulfilled promises of lower running costs have made the cloud model the dominant mode of the 2020s. In the 1990s and early 2000s, an organization requiring an email system was compelled to acquire hardware and software to configure and host their own platform (the Microsoft Exchange email system running on Dell server or VMWare hardware was a common pattern). The availability of Office 365 (later, Microsoft 365) and Google’s G-Suite provided another, attractive option that eliminated the need to manage systems while providing the email function.
A Review of Current Options for Organizations
Although tech industry marketing presents new developments as replacing old, all of the pre-cloud patterns mentioned above still exist. The question is, what makes sense for your organization from the perspectives of:
Cost
Operational complexity
Maintenance complexity
Security and exposure to vulnerabilities
Availability of skilled workers (related to the ability to effectively manage all of the above)
We needn’t include mainframes in this section since they are cost prohibitive and today, intended for specialized, high performance applications.
Client Server (on-premises)
By ‘on-premises’ we are referring to systems that are not cloud-based. Before the cloud era, the client server model was the dominant pattern for organizations of all sizes. Servers can be hosted within a data center the organization owns or within rented space in a colocation facility (a business that provides rented space for the servers of various clients).
Using a client server model requires employing staff who can install, configure and maintain systems. These skills were once common, indeed standard, and salaries were within the reach of many mid-size organizations. The cloud era has made these skills harder to come by (although there are still many skilled and enthusiastic practitioners). A key question is, how much investment does your organization want to make in the time and effort required to build and manage its own system? Additional questions for consideration come from software licensing and software and hardware maintenance cycles.
Sub-categories of client server to consider
Virtualization and Hyper-converged hardware
As mentioned above, the use of virtualization systems, offered by companies such as VMWare, was one method that arose during the heyday of client server to address the need for more concentrated computing power in a smaller data center footprint.
Hyper-converged infrastructure (HCI) systems, combining compute, storage and networking into a single hardware chassis, is a further development of this method. HCI systems and virtualization reduce the required operational overhead. More about this later.
Hybrid architectures
A hybrid architecture uses a mixture of on-premises and off-site, typically ‘cloud’ based systems. For example, an organization’s data might be stored on-site but the applications using that data are hosted by a cloud provider.
Cloud
Software as a Service
Software as a Service platforms such as Microsoft 365 are the most popular cloud services used by firms of all types and sizes, including activist groups. The reasons are easy to understand:
Email services without the need to host an email server
Collaboration tools (SharePoint and MS Teams for example) built into the standard licensing schemes
Lower (but not zero) operational responsibility
Hardware maintenance and uptime are handled by the service provider
The convenience comes at a price, both financial, as licensing costs increase and operational inasmuch as organizations tend to place all of their data and workflows within these platforms, creating deep dependencies.
Build Platforms
The use of ‘build platforms’ like Azure and AWS is more complex than the consumption model of services such as Microsoft 365. Originally, these were designed to meet the needs of organizations that have development and infrastructure teams and host complex applications. More recently, the ‘AI’ hype push has made these platforms trojan horses for pushing hyperscale algorithmic platforms (note, as an example, Microsoft’s investment in and use of OpenAI’s Large Language Model kit) The most common pattern is a replication of large-scale on-premises architectures using virtual machines on a cloud platform.
Although marketed as superior to, and simpler than on-premises options, cloud platforms require as much, and often more technical expertise. Cost overruns are common; cloud platforms make it easy to deploy new things but each item generates a cost. Even small organizations can create very large bills. Security is another factor; configuration mistakes are common and there are many examples of data breaches produced by error.
Private Cloud
The potential key advantage of the cloud model is the ability to abstract technical complexity. Ideally, programmers are able to create applications that run on hardware without the requirement to manage operating systems (a topic outside of the scope of this document). Private cloud enables the staging of the necessary hardware on-premises. A well known example is Openstack which is very technically challenging. Commercial options include Microsoft’s Azure Stack which extends the Azure technology method to hyper converged infrastructure (HCI) hosted within an organization’s data center.
Information Technology for Activists – What is To Be Done?
In the recent past, the answer was simple: purchase hardware and software and install and configure it with the help of technically adept staff, volunteers or a mix. In the 1990s and early 2000s it was typical for small to midsize organizations to have a collection of networked personal computers connected to a shared printer within an office. Through the network (known as a local area network or LAN) these computers were connected to more powerful computers called servers that provide centralized storage and the means through which each individual computer could communicate in a coordinated manner and share resources. Organizations often hosted their own websites which were made available to the Internet via connections from telecommunications providers.
Changes in the technology market since the mid 2000s, pushed to increase the market dominance and profits of a small group of firms (primarily, Amazon, Microsoft and Google) have limited options even as these changes appear to offer greater convenience. How can these constraints be navigated?
Proposed Methodology and Doctrines
Earlier in this document, I mentioned the importance of being intentional about technology usage. In this section, more detail is provided.
Let’s divide this into high level operational doctrines and build a proposed architecture from that.
First Doctrine: Data Sovereignty
Organizational data should be stored on-premises using dedicated storage systems rather than in a SaaS such as Microsoft 365 or Google Workspace
Second Doctrine: Bias Towards Hybrid
By ‘hybrid’ I am referring to system architectures that utilize a combination of on-premises and ‘cloud’ assets
Third Doctrine: Bias Towards System Diversity
This might also be called the right tool for the right job doctrine. After consideration of relevant factors (cost, technical ability, etc) an organization may decide to use Microsoft 365 (for example) to provide some services but other options should be explored in the areas of:
Document management and related real time collaboration tooling
Online Meeting Platforms
Database platforms
Email platforms
Commercial platforms offer integration methods between platforms that make it possible to create an aggregated solution from disparate tools.
These doctrines can be applied as guidelines for designing an organizational system architecture:
The above is only one option. More are possible depending on the aforementioned factors of:
Cost
Operational complexity
Maintenance complexity
Security and exposure to vulnerabilities
Availability of skilled workers (related to the ability to effectively manage all of the above)
I invite others to add to this document to improve its content and sharpen the argument.
Activist Documents and Resources Regarding Alternative Methods
Counter Cloud Action Plan – The Institute for Technology In the Public Interest
Several years ago, there was a mini-trend of soft documentaries depicting what would happen to the built environment if humans somehow disappeared from the Earth. How long, for example, would untended skyscrapers punch against the sky before they collapsed in spectacular, downward cascading showers of steel and glass onto abandoned streets? These are the sorts of questions posed in these films.
As I watched these soothing depictions of a quieter world, I sometimes imagined a massive orbital tombstone, perhaps launched by the final rocket engineers, onto which was etched: Wasted Potential.
While I type these words, billions of dollars have been spent on and barely tabulated amounts of electrical power, water and human labor (barely tabulated, because deliberately obscured) have been devoted to large language model (LLM) systems such as ChatGPT. If you follow the AI critical space you’re familiar with the many problems produced by the use and promotion of these systems – including, on the hype end, the most recent gyration, a declaration of “existential risk” by a collection of tech luminaries (a category which, in a Venn diagram, overlaps with carnival barker). This use of mountains of resources to enhance the profit objectives of Microsoft, Amazon and Google, among other firms not occupying their olympian perches, is wasted potential in frenetic action.
But what of alternative visions? They exist, all is not despair. The dangerous nonsense relentlessly spewing from the AI industry is overwhelming and countering it is a full time pursuit. But we can’t stay stuck, as if in amber, in a state of debunking and critique. There must be more. I recommend the DAIR Institute and Logic(s) magazine as starting points for exploring other ways of thinking about applied computation. Ideologically, AI doomerism is fueled in large measure by dystopian pop sci-fi such as Terminator. You know the story, which is a tale as old as the age of digital computers: a malevolent supercomputer – Skynet (a name that sounds like a product) – launches, for some reason, a war on humanity, resulting in near extinction. The tech industry seems to love ripping dystopian yarns. Judging by the now almost completely forgotten metaverse push (a year ago, almost as distant as the pleistocene in hype cycle time), inspired by the less than sunny sci-fi novel Snow Crash, we can even say that dystopian storylines are a part of business plans (what is the idea of sitting for hours wearing VR goggles if not darkly funny?).
There are also less terrible, even hopeful, fictional visions, presented via pop science fiction such as Star Trek´s Library Computer Access/Retrieval System – LCARS.
In the Star Trek: The Next Generation episode, “Booby Trap” the starship Enterprise is caught in a trap, composed of energy sapping fields, that prevents it from using its most powerful mode of propulsion, warp drive. The ship’s chief engineer, Geordi LeForge, is given the urgent task of finding a solution. LeForge realizes that escaping this trap requires a re-configuration, perhaps even a new understanding, of the ship’s propulsion system. That’s the plot but most intriguing to me is the way LeForge goes about trying to find a solution.
The engineer uses the ship’s computer – the LCARS system – to do a retrieval and rapid parsing of the text of research and engineering papers going back centuries. He interacts with the computer via a combination of audio and keyboard/monitor. Eventually, LeForge resorts to a synthetic, holo mockup of the designer of the ship’s engines, Dr. Leah Brahms, raising all manner of ethical issues but we needn’t bother with that plot element.
I’ve created a high level visualisation of how this fictional system is portrayed in the episode:
The ability to identify text via search, to summarize and read contents (with just enough contextual capability to be useful) and to output relevant results is rather close, conceptually, to the potential of language models. The difference between what we actually have – competing and discrete systems owned by corporations – and LCARS (besides many orders of magnitude of greater sophistication in the fictional system) is that LCARS is presented as an integrated, holistic and scoped system. LCARS’ design is to be a library that enables access to knowledge and retrieves results based on queried criteria.
There is a potential, latent within language models and hybrid systems – indeed, within almost the entire menagerie of machine learning methods – to create a unified computational model for a universally useful platform. This potential is being wasted, indeed, suppressed as oceans of capital, talent and hardware is poured into privately owned things such as ChatGPT. There are hints of this potential found within corporate spaces; Meta’s LLaMA, which leaked online, shows one avenue. There are surely others.
Among a dizzying collection of falsehoods, the tech industry’s greatest lie is that it is building the future. Or perhaps, I should sharpen my description: the industry may indeed be building the future but contrary to its claims, it is not a future with human needs centered. It is possible however, to imagine and build a different computation and we needn’t turn to Silicon Valley’s well thumbed library of dystopian novels to find it. Science fiction such as Star Trek (I’m sure there are others) provide more productive visions
I devote a lot of time to understanding, critiquing and criticizing the AI Industrial Complex. Although much – perhaps most- of this sector’s output is absurd, or dangerous (AI reading emotions and automated benefits fraud determination being two such examples) there are examples of uses that are neither which we can learn from.
This post briefly reviews one such case.
During dinner with friends a few weeks ago, the topic of AI came up. No, it wasn’t shoehorned into an otherwise tech-free situation; one of the guests works with large-scale engineering systems and had some intriguing things to say about solid, real world, non-harmful uses for algorithmic ‘learning’ methods.
Specifically, he mentioned Siemens’ use of machine vision to automate the inspection of wind turbine blades via a platform called Hermes. This was a project he was significantly involved in and justifiably proud of. It provides an object lesson for the types of applications which can benefit people, rather than making life more difficult through algorithm.
You can view a (fluffy, but still informative) video about the system below:
Hermes System Promotional Video
A Productive Use of Machine Learning
The solution Siemens employed has several features which make it an ideal object lesson:
1.) It applies a ‘learning’ algorithm to a bounded problem
Siemens engineers know what a safely operating blade looks like; this provides a baseline against which variances can be found.
2.) It applies algorithms to a bounded problem area that generates a stream of dynamic, inbound data
The type of problem is within the narrow limits of what an algorithmic system can reasonably and safely handle and benefits from a robust stream of training data that can improve performance
3.) It’s modest in its goal but nonetheless important
Blade inspection is a critical task and very time consuming and tedious. Utilizing automation to increase accuracy and offload repeatable tasks is a perfect scenario.
How Is This Different from AI Hype?
AI hype is used to convince customers – and society as a whole – that algorithmic systems match, or exceed the capabilities of humans and other animals. Attempts to proctor students via machine vision to flag cheating, predict emotions or fully automate driving are examples of overreach (and the use of ‘AI’ as a behavioral control tool). I use ‘overreach‘ because current systems are, to quote Gary Marcus in his paper ‘The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence‘, “pointillistic” – often quite good in narrow or ‘bounded’ situations (such as playing chess) but brittle and untrustworthy when applied to completely unbounded, real world circumstances such as driving, which is a series of ‘edge cases’.
Visualization of Marcus’ Critique of Current AI Systems
The Siemens example provides us with some of the building blocks of a solid doctrine to use when evaluating ‘AI’ systems (and claims about those systems) and a lesson that can be transferred to non-corporate uses.